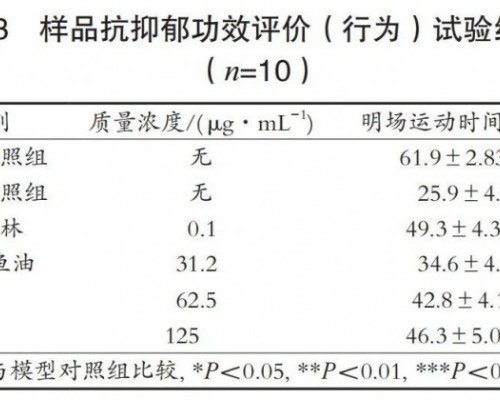
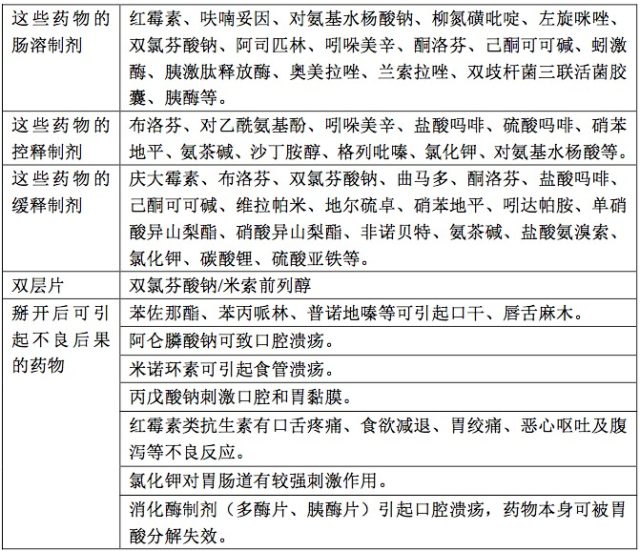
1897年,8岁的Virginia O'Hanlon写信给《纽约太阳报》求证一个问题:“世界上究竟有没有圣诞老人?”这是Virginia的父亲Phillip O'Hanlon博士给孩子出的一个主见,由于“假定《纽约太阳报》给予必定答复,那么现实就是这样”。
而现如今许多临床医师和医疗卫生专家,或许相似地盲目信赖着印刷文字所呈现的“真理”,好像“《新英格兰医学杂志》(NEJM)、《美国医学会杂志》(JAMA)、《柳叶刀》(The Lancet)如此之定论,那么现实就是这样这样的”。
将所谓“圣诞老人”的求证轶事放到一边暂时不管,希腊约阿尼纳大学流行病学与卫生系John Ioannidis等以为,许多医学文献经验证是与现实存在偏倚的,现实上有的乃至是过错的。假定剖析变量X与Y的计算学联络,大都人会揣度以为变量X得出了Y。
可是,下面咱们经过5种状况很容易地就从不同视点对上述问题进行从头解说与知道,以此类推医学文献的是与非。加拿大麦吉尔大学心内科研讨员Christopher Labos博士对这个有意思的论题进行深化剖析,Medscape医学新闻对此进行了报导。现将主要内容编译如下。
1. 反向因果联络
假定变量X与Y之间有联络,那么现实上变量X导致Y、抑或是变量Y导致X皆有平等时机的或许性。在大大都状况下,哪个变量为因、哪个变量为果是清楚明了的。例如,假定某研讨显现“吸烟”与“冠状动脉心脏病(CHD)”之间存在计算学联络,那么揣度成果很清晰,就是“吸烟”导致了“CHD”,而非“CHD”促进了人们“吸烟”。
该例中由于吸烟发作在CHD之前,所以反向因果联络就不树立。但实践状况并非总是那么清晰。以NEJM上所宣布的一篇文章为例,该研讨显现“糖尿病”与“胰腺癌”之间存在相关性,一般读者或许会得出这样的定论:“糖尿病”导致的“胰腺癌”。
可是,进一步剖析则显现,许多糖尿病是于近期发病的。患者先呈现的胰腺癌,肿瘤继发性损坏胰腺中发作胰岛素的胰岛细胞。因此,糖尿病不是胰腺癌的病因,却是后者为前者的病因。
这种在揣度中弄错的因果联络就是“检出征兆偏倚”的一种方式(补白:检出征兆偏倚也称检出信号偏倚,是指某要素如能引起或促进某症状或体征呈现,使患者因此而去就医,这就提高了该病的检出时机,使人误以为某要素与该病有因果联络。这种虚伪联络形成的偏倚称为检出信号/征兆偏倚)。
文献报导中存在很多诸如此类的比如。如对母乳喂食和生长发育缓慢之间的相关假定,实践上实在状况是反映对病重婴儿倾向于挑选更长时刻的母乳喂食。因此,生长发育缓慢导致了喂食时刻延伸,而非其他因果联络。
与之相似,口服雌激素与子宫内膜癌的发病之间就不彻底是外表看起来的那种联络了。关于子宫出血的病例或许会予以口服雌激素处方,而子宫内膜癌本身就或许引起不规则出血。
因此,当患者终究确诊为子宫内膜癌时,外表看起来貌似是口服雌激素在先,癌症发病在后。但现实上却是癌症(患者不知道但症状是子宫出血)促进患者就医而服用雌激素。明显,有时也难以辨明哪一个要素是因、哪一个要素是果。
2. 掷骰子一般的偶尔事情
随意恣意一项研讨,发现有两个变量X和Y之间有相关性,而实践上总是存在着这样一种或许:两者之间仅是随机发作的偶尔事情,进而促成了一个相关算了。
大大都人评价某成果是否为偶尔事情时,依靠于查验计算学目标P值是否小于0.05。可是,现实上也存在多种理由能够解说单纯依靠P值处理问题的过错性。Steven Goodman环绕P值进行过精彩的总述剖析(详见A dirty dozen: twelve P-value misconceptions. Semin Hematol. 2008;45:135-140),关于阅览医学文献的读者而言可谓一篇不容错失的必读文章。
为了阐明这一点,以ISIS-2临床实验为例。该实验成果表明,心梗发作后给予患者阿司匹林可下降逝世率。可是,亚组剖析却意外发现,那些双子座和天秤座的患者没有因此获益,其他星座的患者因服药而获益,且计算学剖析显现P<0.00001。除非咱们情愿从头审视一下所谓“占星学”的科学性,不然咱们不得不供认这一过错成果纯属偶尔。
相同,Counsell等也经过掷3种不同色彩骰子的实验,极好地模仿了理论临床实验及其荟萃剖析的成果。实验要求学生们每人掷1对骰子,6点模仿表明临床实验患者结局逝世,其他数字标志患者持续存活。一起,还奉告学生们其间有一种骰子比另一种骰子“更有用”或“更无效”(就是说能掷出更多的6点,喻指临床实验研讨中患者更易呈现逝世)。
成果果不其然,掷赤色骰子没有发现差异之处,而掷白色和绿色骰子却显现出标志39%的危险下降(P=0.02)。有的学生乃至以为他们的骰子是“灌铅的”。这一发现十分出人意料,由于Counsell只分发给学生们一般的骰子,并跟他们开了一个打趣罢了。但掷白色和绿色骰子(标志不同偏移影响)呈现的差异却是彻底随机的成果。
假阳性的概率
有时想起“偶尔”在计算剖析中能起到如此大的影响,着实令人震慑和不安。如上所述的亚组剖析就是虚伪相关的典型代表。大都研讨人员将查验水平定位为有计算学含义或犯1类过错的概率定位为5%。
可是,进行2项研讨的剖析,至少其间一次剖析发作过错的概率就是9.75%;进行5项研讨的剖析,这一概率就为22.62%;进行10项研讨剖析,其间至少1次是伪相关(即便没有一项研讨为真)的概率就是40.13%。
由于大都文献分出了许多不同亚组和复合结尾,所以发作至少一次伪相关的或许性极高。一般状况下,傍边一种伪相关作为定论宣布出来,其他阴性成果将永无出头之日。
有一种办法能够用来削减呈现这些过错,那就是进行“重复”操作。可是不幸的是,现在医学学术系统并不欢迎对已发布成果的重复验证研讨。若干研讨显现,许多已发布临床实验很或许是忍不住独立实验验证的假阳性成果。
John Ioannidis于2005年宣布了一篇总述文章,对几大医学中心期刊中45项影响广泛的杰出研讨进行检查,成果发现其间24%没有进行重复验证,16%与后续的研讨定论相左,还有16%与开始报导比较样本量更小、查验效能更弱。全体来看,缺乏44%的实验是经过完好重复验证的。
在某种程度上是能够估量到已宣布文献中呈现这些假阳性成果的概率的。假定某种状况下全部估测中有10%实践为真,现以为大都研讨犯1类过错(判别存在相关性而实践上并无相关的概率,即假阳性)的概率为5%、犯2类过错(判别不存在相关性而实践上存在联络,即假阴性)的概率为20%,这是由大都临床实验设定的规范答应过错份额。这样就能够树立如下所示的二联表:
成果为真
研讨
相关
不相关
总数
相关
真阳性
1类过错
不相关
2类过错
真阴性
总数
100
900
1000
按上述二联表刺进数据:
成果为真
研讨
相关
不相关
总数
相关
100*0.80=80
900*0.05=45
125
不相关
100*0.20=20
900*0.95=855
875
总数
100
900
1000
这就意味着,在125项阳性成果的研讨中,仅80/125或64%是真阳性的。因此,有计算学含义的成果中有1/3为纯属偶尔的假阳性。当然,上述成果是树立在假定现在评论的这些研讨为没有偏倚的。
3. 偏倚:“咖啡”、“手机”和“巧克力”研讨比如
当变量X和Y之间没有实在的相关时是会呈现偏倚的,但有一种是由于咱们规划研讨时制造出来的。Delgado-Rodriguez和Llorca发现74种最常见偏倚,大致可概括为2大类:挑选偏倚和信息偏倚。
挑选偏倚的经典比如之一就是1981年宣布在NEJM上的一项研讨,其成果显现饮用咖啡和胰腺癌发病之间存在相关性。该研讨招募对照组时呈现了挑选偏倚,导致对照组呈现消化性溃疡病的份额很高,该组患者为了不加重病况而几乎不饮用咖啡。
由于所选对照组饮用咖啡基线水平与一般人群存在差异,所以对照组饮用咖啡和发作癌症的相关性就这样随便造了出来。当运用适宜的对照组后重复该研讨时,并未发现两者间有联络。
信息偏倚与挑选偏倚不同,当搜集数据或丈量数据存在系统误差或查验露出要素、结局的丈量办法不完美时,可发作信息偏倚。例如,吸烟者奉告研讨人员自己对错吸烟者,或是研讨目标系统性报低或报高本身的身高状况。
有一种特殊状况称为回想误差,主要是查询研讨目标既往的露出状况,由于被查询者回想失真或不完好形成定论的系统误差。
例如,INTERPHONE研讨旨在查询手机与脑肿瘤之间的相关性,检查实验组和对照组手机通话记录发现,两组研讨目标呈现较大且无规律的回想误差,其间实验组目标存在高估更长时刻通话周期的状况。这样误差很大的回想或许导致呈现手机通话和脑肿瘤存在相关性的成果,即便实践上两者并未有联络。
区群过错是另一种有意思的信息偏倚,是指研讨者用一种集群的剖析单位做研讨,而用非集群的剖析单位作定论的现象,即便用全体人群水平的露出状况为单个患者的危险状况下定论。相似的比如就是近期由Messerli在NEJM上宣布的一篇没必要确实的文章,该研讨显现具有较高巧克力消费的国家荣获诺贝尔奖居多。
其间“国家”水平的数据存在的问题在于,“国家”不吃巧克力,且“国家”不会赢得诺贝尔奖;“人”吃巧克力,“人”能荣获诺贝尔奖。这项研讨虽然能够作为趣闻读一读,但该文并没有树立好立论的底子点,就是荣获诺贝尔奖的个别才是“实在吃”巧克力的人。
另一种常见的区群过错比如就是评论身高和逝世率之间的相关性。有很多的总述研讨以为身材矮小与寿数延伸有相关性。可是,其间大都研讨是以国家水平数据进行评论剖析的。丹麦人均匀比意大利人高,冠状动脉心脏病的发病率也更高。
可是,假定在该国调查双胞胎或个别状况,你会发现相反的相关性,即身材矮小的个别更易发作心脏病。相同,过错出在以国家全体而非个人为单位。
4. 稠浊要素
不像偏倚,稠浊常呈现在当变量X和Y之间实在存在相关性之时,但该相关性巨细受第三个变量的影响;偏倚是人为要素形成的,也是搜集数据时不恰当的挑选病例或过错形成的,而稠浊要素是天然存在的。
例如,糖尿病是肾功能衰竭和心脏疾病之间相关性的稠浊要素,由于前者能够形成后两者呈现。虽然肾衰患者有发作心脏病的高危性,但若不考虑糖尿病的固有危险,则会使两者联络看起来强于实在状况。
稠浊是每一项调查性临床研讨普遍存在的一个问题,计算学调整并不能总是除掉这一点。即便某些规划极佳的调查性研讨也败在稠浊要素方面上了。例如,长久以来以为激素替代疗法是女人发作心脏疾病的维护要素,直到“妇女健康建议”随机化临床研讨驳斥了这种观念。
虽然极力进行计算学调整,可是总存在“剩余稠浊”(指那些稠浊要素虽然经过计算学处理,但由于丈量误差的存在,丈量有误的那一部分稠浊发作的效应仍然会曲解露出对结局的实在联络)。可是,简略地把更多变量放入多要素模型中并不一定是更好的办法。过度校对也是一个费事,这样调整非必要变量或许会导致呈现偏倚成果。
实在的随机化可处理稠浊问题
能够经过随机化处理稠浊问题。当将研讨目标纯属偶尔地随机分配至一组或另一组中时,任何稠浊要素(即便是不知道的要素)应该均匀地散布在实验组和对照组中。可是,这是要求树立在实在随机化的根底之上的。
以1996年一项研讨为例,该研讨想要比较腹腔镜和开腹阑尾切除术医治阑尾炎预后的状况。研讨在白地利发展得很顺畅,但在夜班期间,要求必须有行腹腔镜手术的主治医师在场,才能做腹腔镜阑尾切除术。
成果就是,值勤的住院医师不想呼唤他们的主治医师,因此将半透明的随机化分组信封向光处看里边分组状况,做弊辨认患者是开腹手术仍是腹腔镜手术。当他们发现信封里边是分配患者行开腹手术时(不需主治医师在场也更节省时刻),就拆开这个信封并将其他信封放回原处,供第二天早上运用。
由于理论上在夜间承受手术的病例比能够保存等候择期第二天早上手术的病例病况更重,所以值勤住院医师的做弊就使得研讨成果发作了偏倚:病况更重的患者因此做法倾向于行开腹手术,使开腹手术组的预后比实在状况差得多。
因此,虽然一般以为随机化实验是处理稠浊要素的好办法,可是假定没有恰当把握好随机化进程,仍会存在稠浊搅扰。在这种状况下,运用不透明的随机化分组信封也许可处理这个问题。
5. 夸张解说成果的危险
最终,让咱们做一个不大或许的假定:咱们要进行一项实验,其间每个细节都白璧无瑕,也没有呈现上述所谈及的各种问题;最大的问题呈现在咱们对实验成果的解说上。NEJM杂志上曾有过一篇文章,定论称非裔美国人比白人行血管造影的或许性低40%。
该研讨名动一时,但随后Schwartz等指出,这项研讨成果被夸张了。假定研讨者运用比值比替代危险比,那么该研讨的成果就成为7%而非40%,因此其实这篇文章也就不会被推重到这么注目的位置。
能挑选正确的计算查验办法是一项较为困难作业。近20年前,Sackett等曾一度扬言宣称要“打倒比值比!”可是曩昔这么长时刻了,他们仍然还在文章中用着这个计算学目标。
另一个重要问题就是运用“相对危险”仍是“肯定危险”。虽然后者明显定论偏性更重些,可是一项针对约350个研讨的总述剖析却发现,有88%的研讨挑选运用“肯定危险”报导成果。
此外,过度依靠“相对危险”也或许发作误导定论。例如,Baylin等研讨称,饮用咖啡后一小时内发作心肌梗死的相对危险是1.5(即危险添加50%)。该个备受注目的定论被Poole《至修改读者来信》中以尖锐言辞予以驳斥。
Poole将1.5的相对危险度换算成肯定危险,成果就解说为“每饮用200万杯咖啡呈现一次心脏事情”。明显,规划极佳的实验研讨也要放在实践临床布景下解说,一起还要谨记:有计算学含义并不意味着存在临床含义。
质疑之声:何须吃力进行临床实验呢?
综上所述,有人会质疑临床实验或许会呈现种种过错,那么咱们为何还费力进行临床实验呢?由于咱们不肯像文章最初说到的小Virginia那样,信任报纸上刊登的全部信息。咱们并非嫉恶如仇,而至少应对宣布的研讨文章持一个质疑情绪。
质疑是功德,它使咱们不时应战自以为现已证明的、众所周知的事物。假使没有这种质疑的情绪,咱们或许依旧对女人服用激素替代疗法用来防备心脏病,或许依旧在患者心梗后运用I类抗心律异常药物,或许依旧随随意便运用COX-2抑制剂,或许依旧……
征引Fiona Godlee博士在BMJ上宣布的一篇针对循证医学的述评总结:“这是一个有缺点的系统,但仍是咱们现有的最好的系统。”